作者 | Li Yuan
编辑 | 郑玄
资深机器人专家 Eric Jang 不久前曾预言:「ChatGPT 曾在一夜之间出现。我认为,有智慧的机器人技术也将如此。」
他或许说对了。
北京时间 3 月 13 日深夜,一段人形机器人的视频开始在 X 上热传。
之前从未展示过机器人方向能力的 OpenAI,在与投资公司的人形机器人的合作中,第一次展示了自己的机器人智能能力。
Figure,OpenAI 投资的机器人公司,上传了这段视频。在视频中,Figure 的人形机器人,可以完全与人类流畅对话,理解人类的意图,同时还能理解人的自然语言指令进行抓取和放置,并解释自己为什么这么做。
而其背后,就是 OpenAI 为其配置的智能大脑。
在过去一年的具身智能进展中,或许你曾经看过类似的机器人自主决策、拿取物品的展示,但在这段视频中,Figure 人形机器人的对话流畅度、展现出的智能感,接近人类操作速度的动作流畅性,绝对都是第一流的。
Figure 还特意强调,整段视频没有任何加速,也没有任何剪辑,是一镜到底拍摄的。同时,机器人是在完全自主的情况下进行的行为,没有任何远程操纵 —— 似乎在暗暗讽刺前段时间爆火的展现了酷炫机械能力,但是没有太多智能程度的斯坦福炒菜机器人。
比起机器人的智能表现,更可怖的是,这只是 OpenAI 小试牛刀的结果 —— 从 OpenAI 宣布与 Figure 共同合作推进人形机器人领域的前沿,到这个视频的发布,只有短短的十三天。
此次 Figure 人形机器人背后的智能,来自端到端的大语言-视觉模型,这是具身智能领域目前非常前沿的领域。去年极客公园报道过谷歌在类似领域的进展。谷歌做出的端到端机器人控制模型,被一些行业内的人士,誉为机器人大模型的 GPT-3 时刻。
而当时,谷歌的机器人模型,还只能根据对话来做一些抓取,并不能与人类对话,也不能向人类解释自己为什么会这么做。而谷歌自身,从 Everyday Robotics 开始,已经有了五年以上的机器人研究经验。
而 Figure 本身,成立于 2022 年。从 OpenAI 宣布介入与之合作,到今天它们共同推出一个能够自主对话和决策的机器人,只有 13 天。
机器人智能的发展,显然正在加速。
01. 端到端大模型驱动,机器人的速度已经接近人类速度
Figure 的创始人 Brett Adcock 和 AI 团队的负责人 Corey Lynch 在 X 上解释了此次视频中机器人互动背后的原理。
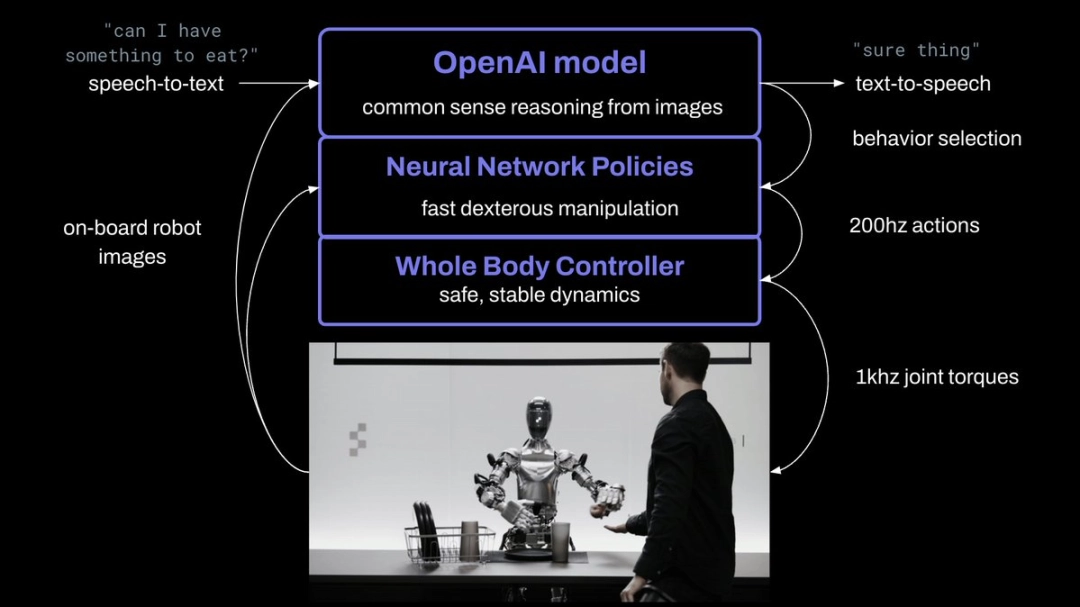
此次的突破,由 OpenAI 与 Figure 共同做出。OpenAI 提供负责提供视觉推理和语言理解,而 Figure 的神经网络提供快速、低水平、灵巧的机器人动作。
机器人所做出的所有行为都是出于已经学习过,内化了的能力,而不是来自远程操作。
研究人员将机器人摄像头中的图像输入,和机载麦克风捕获的语音中的文本转录到由 OpenAI 训练的,可以理解图像和文本的多模态模型(VLM)中,由该模型处理对话的整个历史记录,得出语言响应,然后通过文本到语音的方式将其回复给人类。
同样的模型,也负责决定在机器人上运行哪些学习的闭环行为来完成给定的命令,将特定的神经网络权重加载到 GPU 上并执行策略。
这也是为什么这个机器人,属于「端到端」的机器人控制。从语言输入开始,模型接管了一切处理,直接输出语言和行为结果,而不是中间输出一些结果,再加载其他程序处理这些结果。
Figure 的机载摄像头以 10hz 的频率拍摄图像,然后神经网络以 200hz 输出 24 个自由度动作。
Figure 的创始人提到,这代表机器人的速度已经有显著提高,开始接近人类的速度。
图片来源:Corey Lynch 的 X
OpenAI 的模型的多模态能力,是机器人可以与世界交互的关键,我们能够从视频中展示中看到许多类似的瞬间,比如:
描述一下它的周围环境。
做出决定时使用常识推理。例如,「桌子上的盘子和杯子等餐具接下来很可能会进入晾衣架」。
将「我饿了」等模棱两可的高级请求转化为一些适合上下文的行为,例如「递给对方一个苹果」。
用简单的英语描述 * 为什么 * 它会执行特定的操作。例如,「这是我可以从桌子上为您提供的唯一可食用的物品」。
而模型能力的强大,使其还能够拥有短期记忆,比如视频中展示的「你能把它们放在那里吗?」「它们」指的是什么?「那里」又在哪里?正确回答需要反思记忆的能力。
而具体的双手动作,可以分成两步来理解:
首先,互联网预训练模型对图像和文本进行常识推理,以得出高级计划。如视频中展示的:Figure 的人形机器人快速形成了两个计划:1)将杯子放在碗碟架上,2)将盘子放在碗碟架上。
其次,大模型以 200hz 的频率生成的 24-DOF 动作(手腕姿势和手指关节角度),充当高速「设定点(setpoint)」,供更高速率的全身控制器跟踪。全身控制器确保安全、稳定的动力,如保持平衡。
所有行为均由神经网络视觉运动 Transformer 策略驱动,将像素直接映射到动作。
02.从 ChatGPT 到 Sora,再到机器人,OpenAI 想包揽「智能」这件事
2021 年夏天,OpenAI 悄悄关闭了其机器人团队,当时,OpenAI 曾宣布无限期终止对机器人领域的探索,原因是缺乏训练机器人使用人工智能移动和推理所需的数据,导致研发受到阻碍。
但显然,OpenAI 并没有放下对这个领域的关注。
2023 年 3 月,正在一年前,极客公园报道了 OpenAI 投资了来自挪威的机器人制造商 1X Technologies。其副总裁正是我在文初提到的,认为具身智能将会突然到来的 Eric Jang。
而无独有偶,1X Technologies 的技术方向,也是端到端的神经网络对于机器人的控制。
而今年 3 月初,OpenAI 和其他投资人一起,参与了 Figure 的 B 轮融资,使其成立两年,就达到了 26 亿美金估值。
也正是在这一轮融资之后,OpenAI 宣布了与 Figure 的合作。
Figure 的创始人 Brett Adcock,是个「擅长组局」的连续创业者,整个职业生涯中创立过至少 7 家公司,其中一家以 27 亿美元的估值上市,一家被 1.1 亿美元的价格收购。
创建公司后,他招募到了研究科学家 Jerry Pratt 担任首席技术官,前波士顿动力 / 苹果工程师 Michael Rose 担任机器人控制主管。此次进行分享的 AI 团队负责人 Corey Lynch,则原本是 Google Deepmind 的 AI 研究员。
Figure 宣布自己在电机、固件、热量、电子产品、中间件操作系统、电池系统、执行器传感器、机械与结构方面,都招募了硬核的设计人才。
公司的确进展很快。在与 OpenAI 合作之前,已经做出了不少成绩。2024 年 1 月,Figure 01(Figure 的第一款人形机器人) 学会了做咖啡,公司称,这背后引入了端到端神经网络,机器人学会自己纠正错误,训练时长为 10 小时。
Figure 01 引入 AI 学会做咖啡 | 图片来源:Figure
2 月,公司对外展示 Figure 01 的最新进展,在视频里,这个机器人已经学会搬箱子,并运送到传送带上,但速度只有人类的 16.7%。
甚至在商业化上,也已经迈出了第一步:Figure 宣布与宝马制造公司签署商业协议,将 AI 和机器人技术整合到汽车生产中,部署在宝马位于南卡罗来纳州斯巴达堡的制造工厂。
而在今天的视频展示推文中,Figure 宣布其目标是训练一个世界模型,最终能够卖出十亿个级别的模型驱动的人形机器人。
不过,尽管 OpenAI 与 Figure 的合作进展顺畅,但看起来 OpenAI 并未把宝压在一家机器人公司。
北京时间 3 月 13 日,来自谷歌研究团队、加州大学伯克利分校、斯坦福大学教授等一群研究者新成立的一家机器人 AI 公司 Physical Intelligence,被彭博社爆料也拿到了 OpenAI 的融资。
毫无意外,该公司,也是研究未来能够成为通用机器人系统的人工智能。
多头下注机器人领域,13 天合作做出领先的机器人大模型,OpenAI 在机器人领域意图为何,引人关注。
智能人形机器人,未来不止看马斯克的了。
本文来自微信公众号:极客公园 (ID:geekpark),作者:Li Yuan
 RSS订阅
RSS订阅